

Inhaltsverzeichnis
Text zum Ignorieren hinzufügen
Die Text‑Ignorier‑Regel verhindert, dass bestimmter Text unter von Ihnen definierten Bedingungen übersetzt wird.
Dies ist in der Regel die erste Regel, die Sie zu Ihrer Website‑Übersetzung hinzufügen, um beispielsweise Ihr Produkt‑ oder Firmennamen auszuschließen. Um eine solche Regel hinzuzufügen, verbinden Sie sich mit Ihrem Linguise‑Dashboard > Klicken Sie auf Regeln > Neue Regel hinzufügen.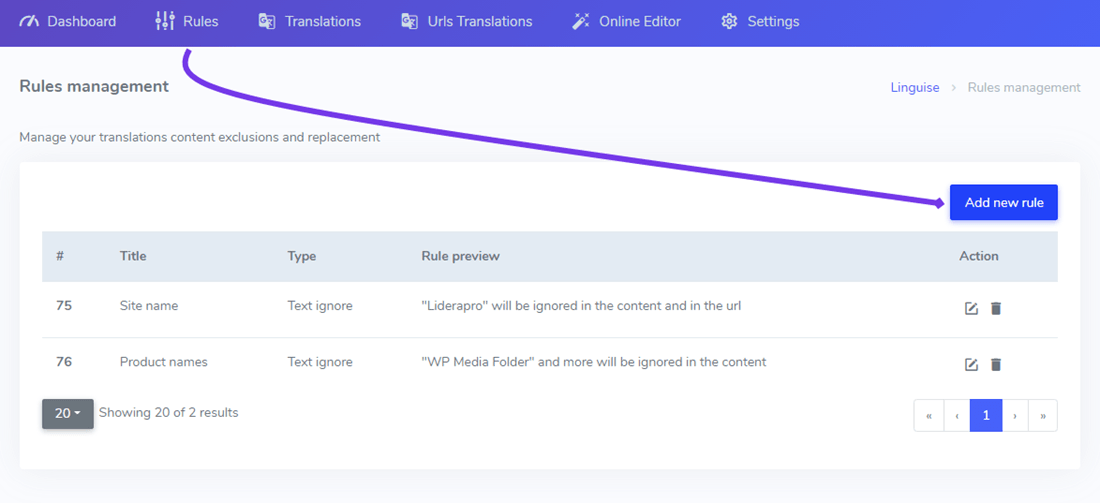
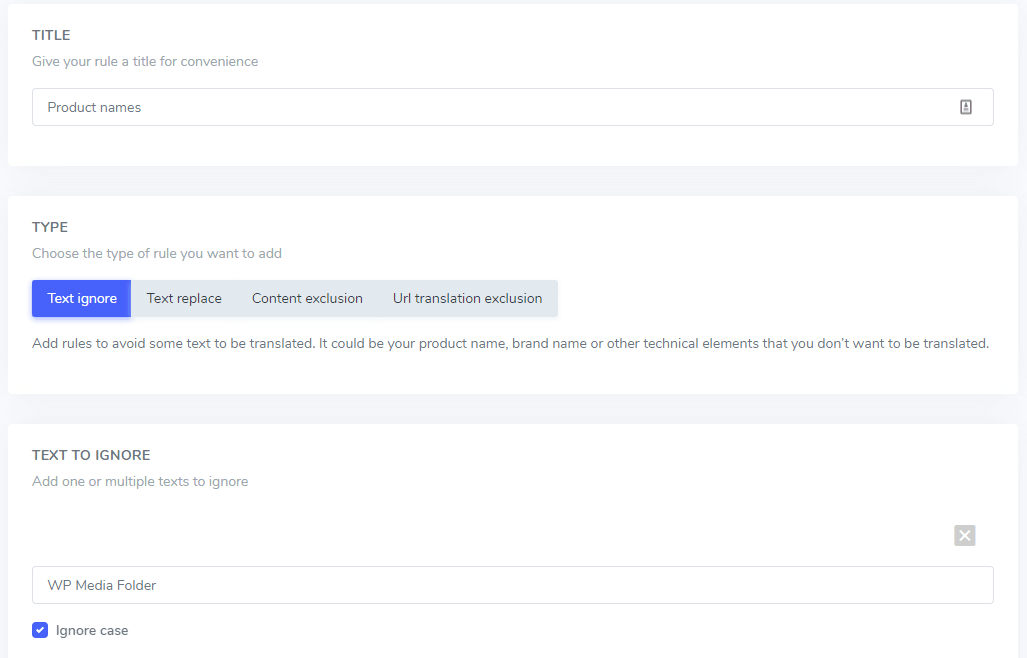
Sie können dann die Details der Textausnahme-Regel aktualisieren, hauptsächlich:
- Der Text, den Sie ausschließen möchten
- Die Bedingungen des Texte-Ausschlusses
- Der Regeltitel (nur für Sie im Linguise-Dashboard sichtbar)
Im Feld „Text zu ignorieren“ können Sie mehrere Textausdrücke hinzufügen, die unter derselben Regel ausgeschlossen werden sollen. In unserem Beispiel sieht der Bildschirm mit mehreren Markennamen‑Ausschlüssen folgendermaßen aus:
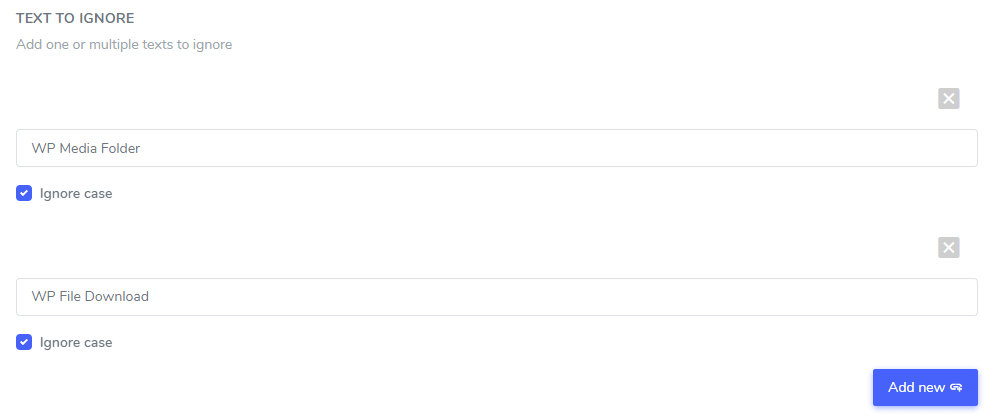
Groß-/Kleinschreibung ignorieren: Die Texteingabe ist case-sensitive, was bedeutet, dass wenn das Kontrollkästchen aktiviert ist, die Regel wird Großbuchstaben und Kleinbuchstaben als gleich behandeln. Beispiel für einen Übersetzungsausschluss: “PrimeVideo player” und “primevideo player” mit nicht aktivierter case-sensitive werden beide ausgeschlossen.
Text nach URLs ignorieren
Sobald you’ve den Text zum Ignorieren von der Übersetzung eingerichtet haben, können Sie den Text auf allen URLs Ihrer Website (unter Verwendung der Option ALL URL) oder auf einigen spezifischen Seiten-URLs ausschließen.
- Original-URL / Übersetzte URL: Ignoriere den Text der Übersetzung für eine bestimmte URL aus der Originalsprache oder für eine bestimmte URL aus einer übersetzten Sprache
- Wildcard / Regulärer Ausdruck: Ignoriere den Text der Übersetzung für eine bestimmte URL unter Verwendung von Wildcard oder regulärem Ausdruck
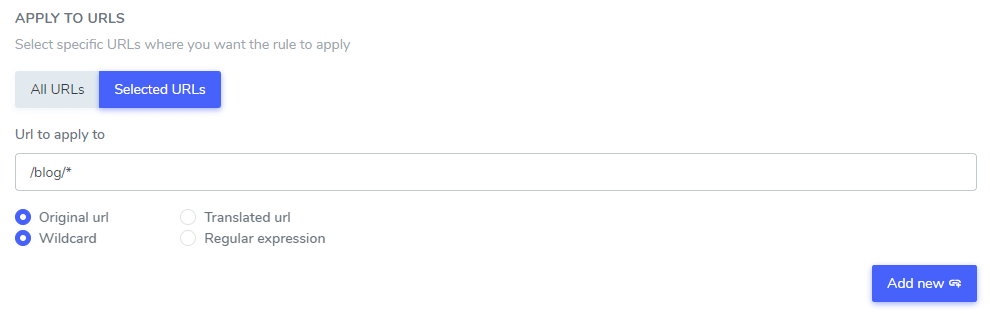
In diesem Beispiel: “Netflix‑Player”, “PrimeVideo‑Player”, “YouTube‑Player” wird von der Übersetzung in ALLEN Website‑URLs ausgeschlossen, die mit www.domain.com/blog/ beginnen
Mehrere URL-Bedingungen können kombiniert werden, um zum Beispiel mehrere übersetzte Sprach-URLs abzudecken.
Musterabgleich mit regulären Ausdrücken
Verwenden reguläre Ausdrücke (RegEx) erfordert ein gewisses Verständnis der Syntax und Konzepte einbezogen. Reguläre Ausdrücke haben unterschiedliche Syntax für URLs und Wörter.
Während Platzhalter einfacher zu verstehen und für einfache Aufgaben zu verwenden sind, bietet RegEx fortgeschrittenere und flexiblere Mustererkennungsfähigkeiten.
Hier’s einige gängige Beispiele für Wort‑Übereinstimmungs‑Muster regulärer Ausdrücke:
- Übereinstimmung jedes Wortes, das mit “Light” beginnt:
RegEx: Light\w
Erklärung: Findet jedes Wort, das mit “Light” beginnt, gefolgt von null oder mehr Wortzeichen (\w). Dies könnte “Light”, “Lightbulb”, “Lightweight”, usw. treffen. - Match any word ending with “Light”:
RegEx: \w*Light
Explanation: Matches any word that ends with “Light” preceded by zero or more word characters. This could match “Sunlight”, “Daylight”, “Spotlight”, etc. - Match “Linguise” as a whole word:
RegEx: \bLinguise\b
Explanation: This will match any string that consists of exactly the characters “Linguise” word. This will also ensure it doesn’t match with other words like LinguiseApp but only “Linguise”.
Weitere Details zu regulären Ausdrücken finden Sie hier: https://www.regular-expressions.info/
Wenn Sie darüber verwirrt sind, empfehlen wir die Verwendung Wildcard über reguläre Ausdrücke für den regulären Gebrauch.
Wenn Sie Bedenken haben, können Sie uns jederzeit kontaktieren, indem Sie das Kontaktformular ausfüllen!
Text nach Sprache ignorieren
Der ignorierte Text, den Sie hinzugefügt haben, kann nur in einer bestimmten Sprache oder in allen Sprachen ausgeschlossen werden. Das ist ziemlich praktisch, da einige Wörter in verschiedenen Sprachen dieselbe Schreibweise haben können, aber nur in einer ausgeschlossen werden müssen. Zum Beispiel ist das Wort “ilimitados” im Portugiesischen und im Spanischen gleich.
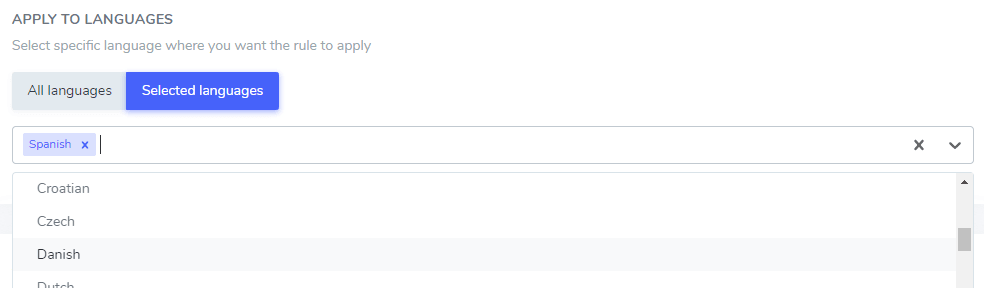
In diesem Beispiel: “Netflix player”, “PrimeVideo player”, “YouTube player” werden nur im Spanischen von der Übersetzung ausgeschlossen.
Ignoriere Text im HTML-Inhalt
Der ignorierte Text, den Sie ’hinzugefügt’ haben, kann von einem Teil Ihres HTML-Inhalts ausgeschlossen werden, indem ein oder mehrere CSS-Selektoren verwendet werden. Mit dem Code-Inspektor Ihres Browsers erhalten Sie beliebige CSS-Selektoren und fügen sie wie folgt hinzu.
CSS-Selektor abrufen:

Und fügen Sie es in der Regelkonfiguration hinzu:
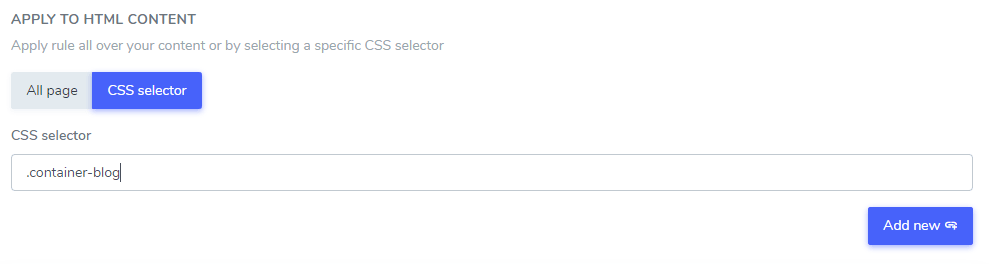
In diesem Beispiel: “Netflix player”, “PrimeVideo player”, “YouTube player” werden nur im HTML-Inhalt, der sich im .blog CSS-Selektor befindet, von der Übersetzung ausgeschlossen
Ignoriere Text im URL‑Inhalt
Der von Ihnen hinzugefügte Text‑Ignorier‑Eintrag kann von einer URL selbst ausgeschlossen werden, was bedeutet, dass “PrimeVideo player” in URLs unverändert bleibt. Zum Beispiel: “www.domain.com/prime-video-player” wird nicht übersetzt.

URL-Änderung: Vorsicht vor einer Konfiguration, die URLs im Live-Website-Inhalt ändert. Sie’ll 404-URLs umleiten müssen
Übersetzung von Inhalten mit einem Tag ausschließen
Sie können ein Tag überall in Ihrem HTML-Inhalt einfügen, um es von der Übersetzung auszuschließen: translate=”no”
Der gesamte Inhalt, der sich unter dem HTML-Container befindet, wird NICHT übersetzt, einschließlich aller Unterelemente.
Beispiel für HTML-Ausschluss per Tag:
<div translate=”no”>
<p>Dieser Text wird überhaupt nicht übersetzt</p>
</div>