

Оглавление
Добавить текст для игнорирования
Правило игнорирования текста предотвратит перевод определённого текста при заданных вами условиях.
Обычно это первый тип правила, которое вы добавляете в перевод сайта, чтобы исключить, например, название продукта или компании. Чтобы добавить такое правило, подключитесь к вашему Панель управления Linguise > нажмите на Правила > Добавить новое правило.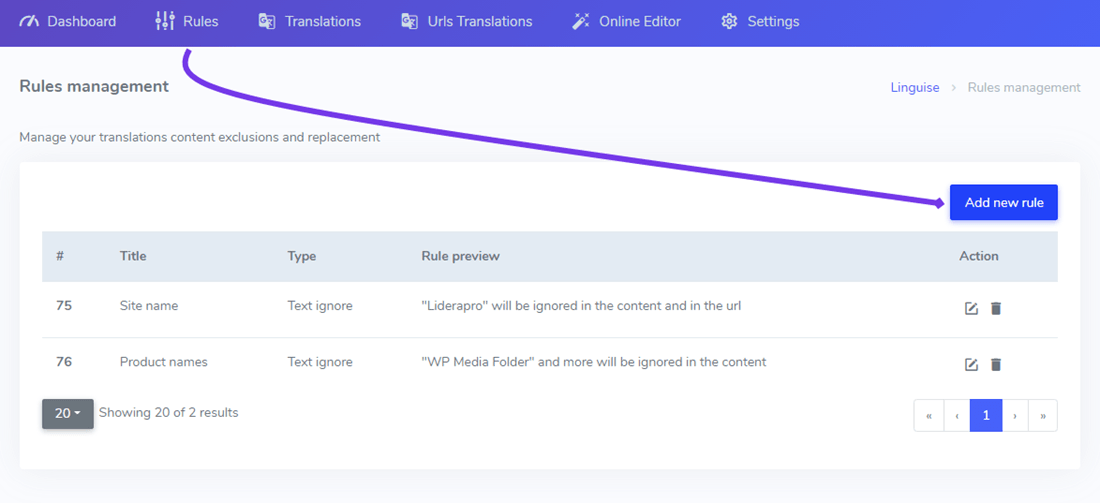
Вы сможете обновить детали правила игнорирования текста, в основном:
- Текст, который вы хотите исключить
- Условия исключения текста
- Заголовок правила (виден только вам в панели Linguise)
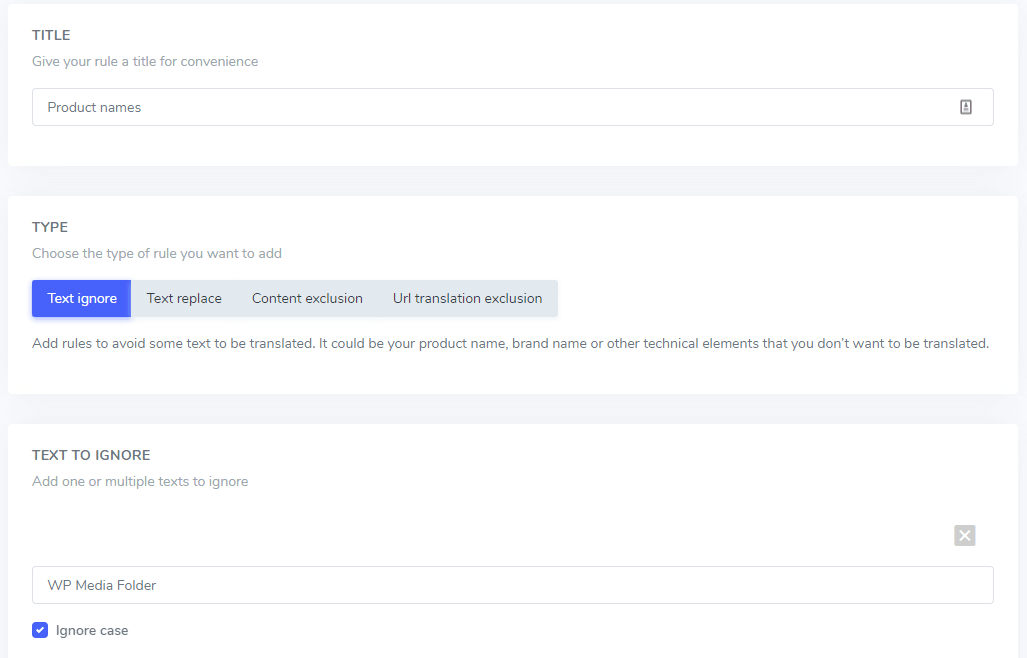
В поле «Текст для игнорирования» вы можете добавить несколько текстовых выражений, которые будут исключены по тому же правилу; следуя нашему примеру, экран с исключением нескольких брендов будет выглядеть так:
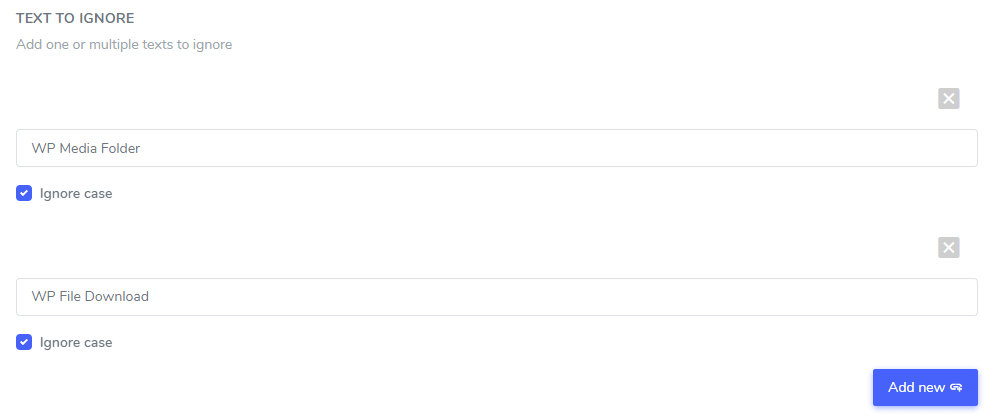
Игнорировать регистр: ввод текста чувствителен к регистру, что означает, что если флажок отмечен, правило будет интерпретировать заглавные и строчные буквы как одинаковые. Пример исключения из перевода: “PrimeVideo player” and “primevideo player” с отключённой чувствительностью к регистру оба будут исключены.
Игнорировать текст по URL-адресам
После того как вы’ve настроили игнорирование текста от перевода, вы можете исключить текст на всех URL-адресах вашего сайта (используя опцию ALL URL) или на некоторых конкретных страницах URL.
- Исходный URL / Переведённый URL: Игнорировать текст перевода на конкретном URL из исходного языка или на конкретном URL из переведённого языка
- Шаблон / Регулярное выражение: Игнорировать текст перевода на конкретном URL, используя шаблон или регулярное выражение
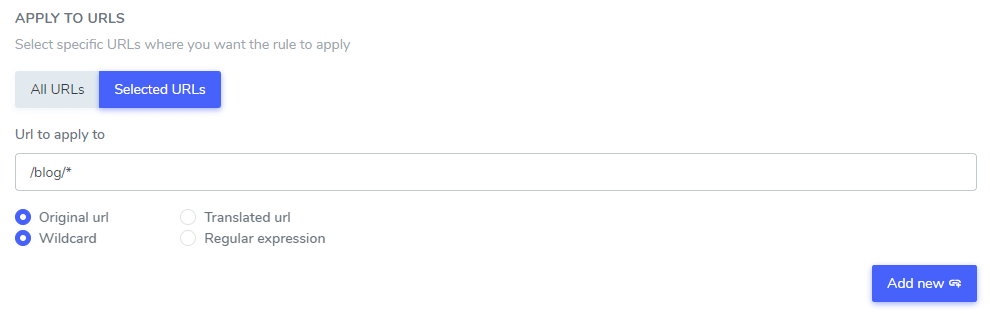
В этом примере: “плеер Netflix”, “плеер PrimeVideo”, “плеер YouTube” будут исключены из перевода на ВСЕХ URL‑адресах сайта, которые начинаются с www.domain.com/blog/
Несколько условий URL могут быть объединены, например, несколько URL переведённых языков.
Сопоставление шаблонов регулярных выражений
Использование регулярные выражения (RegEx) требует некоторого понимания синтаксиса и концепций вовлеченных. Регулярные выражения имеют разный синтаксис для URL и слов.
Хотя подстановочные знаки проще понять и использовать для простых задач, RegEx предоставляет более продвинутые и гибкие возможности сопоставления шаблонов.
Вот’ некоторые общие примеры шаблона сопоставления слов регулярного выражения:
- Найти любое слово, начинающееся с “Light”:
RegEx: Light\w
Объяснение: Находит любое слово, начинающееся с “Light” за которым следуют ноль или более символьных знаков (\w). Это может совпасть с “Light”, “Lightbulb”, “Lightweight”, и т.д. - Найдите любое слово, заканчивающееся на “Light”:
RegEx: \\w*Light
Объяснение: Подбирает любое слово, которое заканчивается на “Light”, предшествующее нулю или более символов слова. Это может быть “Sunlight”, “Daylight”, “Spotlight”, и т.д. - НайтиLinguiseкак отдельное слово:
RegEx: \\bLinguise\\b
Объяснение: Это будет соответствовать любой строке, состоящей точно из символов “Linguise”. Это также гарантирует, что не будет совпадений с другими словами, например LinguiseApp, а только с “Linguise”.
Вы также можете прочитать более подробную информацию о регулярных выражениях здесь: https://www.regular-expressions.info/
Если вы’запутались в этом, мы рекомендуем использовать Подстановочный вместо регулярного выражения для обычного использования.
Если у вас есть какие‑либо вопросы, вы всегда можете связаться с нами, заполнив форму обратной связи!
Игнорировать текст по языку
Текст, который вы добавили, можно исключить только в некоторых конкретных языках или во всех языках. Это довольно удобно, так как некоторые слова могут иметь одинаковое написание в разных языках, но требовать исключения только в одном. Например, слово “ilimitados” одинаково в португальском и испанском.
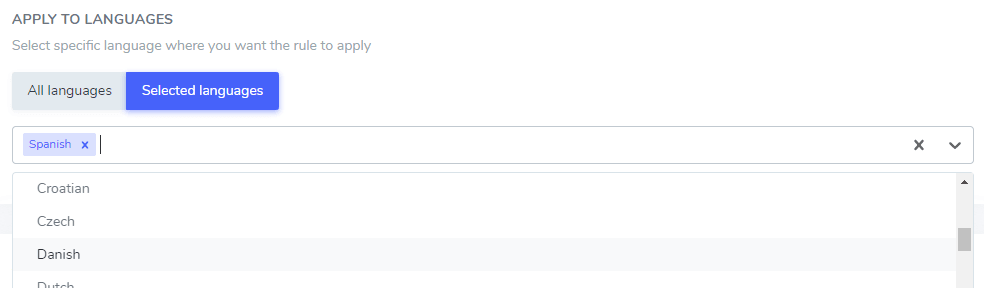
В этом примере: “Netflix player”, “PrimeVideo player”, “YouTube player” будут исключены из перевода только в испанском.
Игнорировать текст в HTML-контенте
Добавленный вами игнорируемый текст можно исключить из части вашего HTML-контента, используя один или несколько CSS-селекторов. С помощью инспектора кода в браузере вы получаете любой CSS-селектор и добавляете его как указано ниже.
Получить CSS-селектор:

И добавьте его в настройку правила:
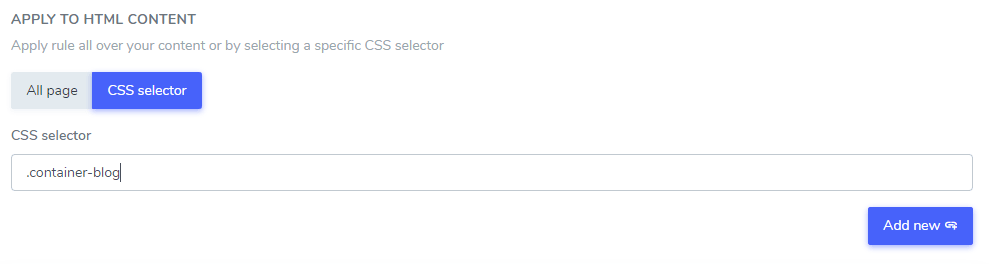
В этом примере: “Netflix player”, “PrimeVideo player”, “YouTube player” будут исключены из перевода только в HTML‑контенте, который находится в селекторе CSS .blog
Игнорировать текст в URL
Добавленный вами игнор текста может быть исключён из самого URL, что означает, что “PrimeVideo player” останется как есть в URL. Например: “www.domain.com/prime-video-player” won’t be translated.

Модификация URL: будьте осторожны с конфигурацией, которая изменяет URL‑адреса в живом содержимом сайта. Это может привести к 404 URL you’ll понадобится перенаправить
Исключить перевод содержимого с помощью тега
Вы можете включить тег где угодно в вашем HTML‑контенте, чтобы исключить его из перевода: translate=”no”
Весь контент, найденный внутри HTML‑контейнера, НЕ будет переведён, включая все вложенные элементы.
Пример исключения HTML по тегу:
<div translate=”no”>
<p>Этот текст не будет переведен вовсе</p>
</div>